True Zero Downtime HAProxy Reloads: An Alternative Approach
Recently, this blog post circulated around the tech Twittersphere:
http://engineeringblog.yelp.com/2015/04/true-zero-downtime-haproxy-reloads.html
It’s an excellent write-up from Yelp about how to get truly zero downtime from HAProxy, which I recommend reading. It’ll work for a lot of scenarios, but unfortunately, it doesn’t work for the one we experience at Unbounce.
The Problem
Early this year, we rolled out HAProxy for SSL offload on our page servers, and encountered the same problem Yelp did. Unbounce hosts landing pages for thousands of customer domains, so we need thousands of SSL certificates. HAProxy 1.5 supports multiple domains on a single IP using SNI (Server Name Indication). However, HAProxy takes a significant amount of time and CPU to load certificates.
The first solution we investigated was the same one Yelp did: Dropping SYN packets during the reload. During our testing we found that loading certificates can take long enough that this approach isn’t feasible. Loading certificates only utilizes a single CPU core, at 100%. Loading 1000 certs takes about 2 seconds, regardless of how many cores the machine has. It scales linearly, so loading 10000 certificates takes about 20 seconds. Obviously with the potential for 20+ second reloads, dropping SYN packets for that long is unfeasible.
Having a 20 second rather than 50 millisecond window to deal with pushed us in rather a different direction than Yelp went (though they did consider it). We call what we developed the “IP tableflip”.
The Solution: IP Tableflip

Halloween at Unbounce
It actually started as a joke. Let’s run two HAProxy instances, and somehow switch between them. Ha ha, funny, right? But… maybe it would work? (Spoiler: it does.)
We already had an ELB (Elastic Load Balancer) in front of a number of page server instances, and now we’re running HAProxy (two instances of it) on those page server instances as well, purely for SSL offload. We use Linux’s iptables to switch which HAProxy instance (blue or green) the ELB talks to, by changing which instance the “outside” ports are redirected to.
Our process for updating certificates looks something like this:
- Every 5 minutes, sync our local cert directory from the remote storage.
- If there weren’t any changes, job’s done.
- Reload the inactive HAProxy instance with “service haproxy-[colour] reload”
- Insert an iptables rule to direct traffic to the new HAProxy colour.
- Delete the iptables rule directing traffic to the old HAProxy colour.
Our automated load tests allowed us to easily graph the error-rate with a single HAProxy, compared to the same load test scenario with IP tableflip, reloading every 5 minutes:
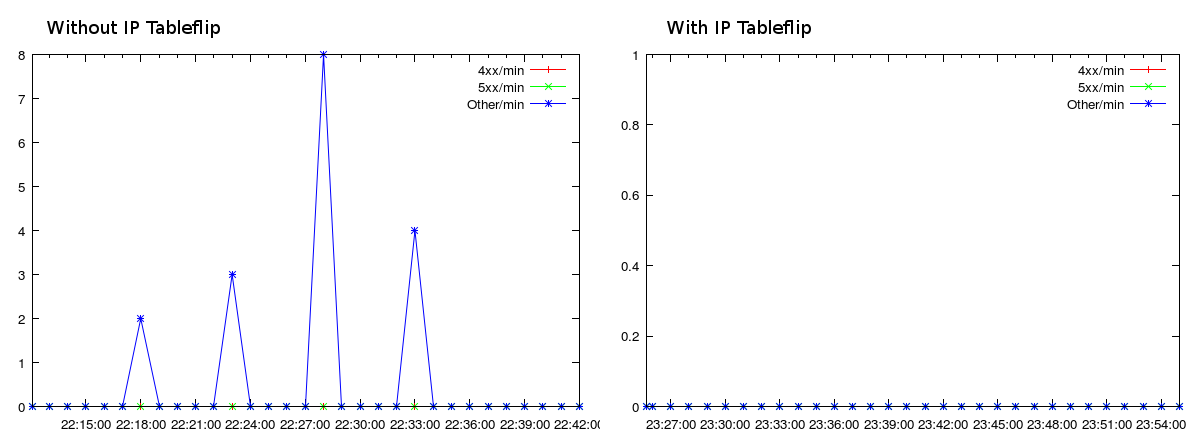
Total number of errors in the preceding minute
I’ve posted a snippet of our script for restarting HAProxy with zero downtime on gist: https://gist.github.com/lewisd32/0fcaee94702c97dd5387
Iptables uses a module called “conntrack” to track connections, so even after the rule directing traffic to the old colour is deleted, any packets that come in on that socket will continue to be routed to the old colour HAProxy. Our connection keep-alive time is fairly short, so there’s no risk that these connections to the old HAProxy would live long enough to see the next reload, in 5 minutes.
All this does come at a cost, unsurprisingly. Since implementing this, we’ve seen an approximately 10ms increase in latency in our load testing:
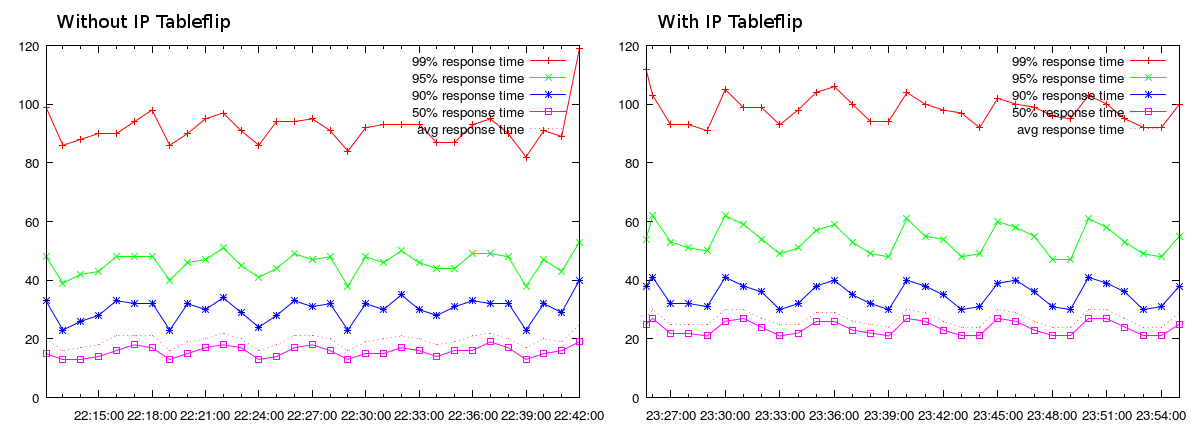
50k certs, 110k requests/min. Percentiles for responses in the preceding minute.
(The wave pattern of the graph is due to the HAProxy reload using 100% of one of the two cores. With 50k certificates, reloads take around 100 seconds.)
We suspect it’s possible to reduce or eliminate the additional 10ms latency with tuning, but with a 95%ile latency of close to 55ms, it hasn’t been a priority.
This has been running in production since January, and we’re pleased with how well it’s working. Many thanks to Yelp for sharing their findings in their blog post, which encouraged me to (finally) write this.
–Derek Lewis
Senior Software Developer