Growing our AWS Messaging Patterns
At Unbounce, we’re on a constant quest for improving our infrastructure in order to deliver the best service possible to our users. Our goal is to achieve four to five nines availability for our services, while planning for an order of magnitude more traffic. What is perceived externally as a set of services (page builder, page server…) is composed internally of a set of applications that interact with each other. Over time, we rolled out more awesome features and, progressively, these applications became bigger and sometimes more tangled together.
To match our business goals, we have to increase the resiliency and scalability of our applications and, for that matter, we’ve decided to set afoot a progressive evolution of our architecture towards a Service Oriented Architecture (aka SOA). If you have had a close encounter with big IT vendor solutions, SOA can be a dreaded term, especially because of its unfortunate association with SOAP, the XML/HTTP protocol that most developers now love to hate. But for us, SOA means more resilience and more reliability, which actually is the true intention of the approach. By breaking down big applications into smaller chunks offered as services, we will increase the overall availability of the system, as the failure of one part will not entail the failure of it all… at least if the services are not tightly coupled together!
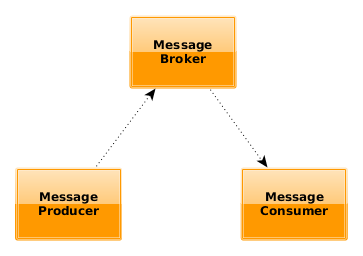 This is when messaging comes into play: messaging (aka message queueing) allows applications or services to interact with each other in a loosely coupled fashion. The producer continually generates messages for the broker, completely unaware of the status of the message consumer. This is possible because the message broker provides a clean interface between the two. This post details some of our decisions regarding the usage of messaging with our cloud provider (AWS).
This is when messaging comes into play: messaging (aka message queueing) allows applications or services to interact with each other in a loosely coupled fashion. The producer continually generates messages for the broker, completely unaware of the status of the message consumer. This is possible because the message broker provides a clean interface between the two. This post details some of our decisions regarding the usage of messaging with our cloud provider (AWS).
You can expect further posts with more findings, joys and, potentially, even tears… But for now, let’s get started with a first round of patterns!
Message Consumers
 This is the most straightforward messaging pattern: it applies typically to asynchronous services, which do not provide an immediate response when being invoked. As represented in the figure, consumers receive messages from a single queue, which is their dedicated channel of communication. Communicating with such services is done by publishing a message to their specifically assigned queue. Simple Queue Service (aka SQS) is the message queue broker we use in AWS.
This is the most straightforward messaging pattern: it applies typically to asynchronous services, which do not provide an immediate response when being invoked. As represented in the figure, consumers receive messages from a single queue, which is their dedicated channel of communication. Communicating with such services is done by publishing a message to their specifically assigned queue. Simple Queue Service (aka SQS) is the message queue broker we use in AWS.
Asynchronous services are fit to act as background workers because they’re fed by a single inbound message queue, which ensures an automatic distribution of messages, hence workload, across workers. We leverage this approach for our new page import/export feature: when a user requests a page download, we queue the request and process it asynchronously because it is an operation that takes a while.
So what happens to the result of such an asynchronous service?
Asynchronous Results
Services are obviously called for a reason: we expect them to perform a certain amount of work that will typically produce a result. For synchronous services the result is provided as an immediate response to the request. For asynchronous services it’s a different story: there’s no interaction waiting for a response. What can we do when another service is interested in the result? We could be tempted to have the asynchronous service call the service interested by its results directly. Can we do that? Yes we can… but we shouldn’t! As integration maven Ross Mason often says:
Point-to-point integration is evil.
Indeed, point-to-point integration is a form of tight coupling that introduces undesirable rigidity in an architecture. Thus, if the outcome of an asynchronous service needs to be provided to another service, it should be done without establishing a direct relationship between these services. This can be done either by:
- Using a routing-slip, i.e. having the message contain the intended destination for the service result, which can be anything from an endpoint URI, a queue ARN (i.e. unique identifier) or an email address,
- Publishing the result to a message fanout, i.e. broadcast it and let subscribers decide what to do with it. One could be tempted to have such services results published directly to a dedicated queue, but that would create an architectural challenge. Though perceived as a generic result queue for the service, this queue would only be consumable by a single consumer, since a message can be delivered to only one consumer. This means that the queue would act as a point-to-point integration between services, something we want to avoid as explained above.
Let’s delve in the latter option by discussing another important messaging pattern: message producers.
Message Producers
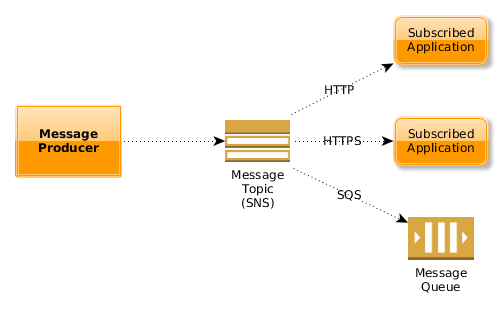
Services can produce messages not only as a result of consuming and processing inbound messages (which we just discussed), but also as the outcome of any application-related or time-triggered event.
For these kind of event producing applications, we’ve opted for using message fanouts as the destination for published messages.
In messaging lingo, a fanout is a particular type of publish-subscribe channel where each published message is distributed to all of the subscribers. It’s sometimes referred to as a topic (as is the case in AWS) but, canonically speaking, topics are a specialized form of fanouts where routing rules are applied to message distribution (for example, to subscribe to messages related to “sports” only in an “news” publish-subscribe channel).
As shown in the illustration, we’re using Simple Notification Service (aka SNS) as our message fanout broker: this broker allows interested applications to subscribe via HTTP, HTTPS or SQS endpoints (the latter meaning that a message consuming service could subscribe its inbound queue to a producer’s output fanout).
Because the responsibility of the message producing application stops at interacting with SNS and because it has no knowledge of what applications are actually subscribed to its output fanout (or not), we do not create any point-to-point integration between applications which is a big architectural win. We’re using this approach for our new page server, which will publish form submission events and log entries to dedicated message fanouts.
Another big win from this approach is that it opens the door for technical and functional serendipity. By this I mean that new usage for the published messages can be found later on, whether for purely technical reasons or to satisfy new business needs, and can be implemented without having to intervene on the message producer. This is very important for a business like ours where we want to be able to roll out new features quickly, but without accumulating technical debt. We’re already thinking of new cool stuff we could do with the fanouts we’ve put in place!
Now, would it make sense for an application or service to use a fanout as an inbound message source? You bet it does, read on to find why.
Message Multicasts
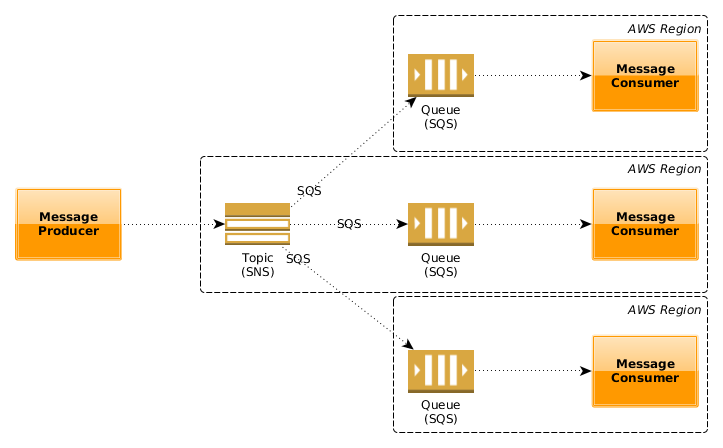 Consider a service that is distributed around the world. It might be running in Oregon and Southeast Asia. Each location has it’s own queue.
Consider a service that is distributed around the world. It might be running in Oregon and Southeast Asia. Each location has it’s own queue.
What if we want all queues at all locations to receive the same message? Enter the inbound message fanout! In this pattern, SQS queues in different regions are subscribed to one SNS topic in one region. Any application wanting to send a message to one application in all regions needs only to publish a message to the SNS topic, the latter would then take care of routing a copy of the message to all relevant queues (effectively “multicasting” it). Such an application could be in any region, as it is allowed to send messages to SNS across regions.
We rely on this pattern to push dynamic configuration changes to all our page servers.
Re-entry Checklist
Here are a few things that we learned and how we would like to see them improved so others won’t have to hit the same turbulence:
- If you use an HTTPS subscription to SNS, make sure your certificate authority is in this list otherwise the registration will silently fail. It would be great if the SNS interface could show the latest failure message when attempting to confirm a subscription.
- Again, when using HTTP/HTTPS subscription, if you use rules in a security group to restrict access to an endpoint, it’s not trivial to find out the IP address range used by SQS (or its security group, if that even exists?) when calling your endpoint. Simplifying this configuration within and across regions would be awesome.
- It is not possible to create SNS to SNS nor SNS to SQS subscriptions. But if these would, one day, become possible, think of the amazing messaging topologies you’d be able to deploy in AWS!
So Amazon, if we promise to be good, could we get these for Christmas? Or even before if we don’t pout?
And what about you? Do you have any particular messaging pattern you’re using, with AWS or not, that you’d like to share with us?