Approaches to split the Monolith
At Unbounce, we always strive to deliver great products to our customers, and at the same time we make big efforts to use techniques and approaches that solve their needs in the best way possible. Lately we have been moving our platform from a Monolithic Architecture to a Service Oriented Architecture (SOA) as we believe this will make a big difference around performance, availablity and fast releases of new features.
There is a lot that has been said about the benefits and gotchas of this journey, so we are not going to repeat ourselves.
Unbounce is particularly interested in using SOA for the following reasons:
- It allows different teams to release features faster, by separating the development life cycle of different components.
- The complexity of features gets reduced considerably, because each service is intended to focus in one part of the problem only.
- It provides the possibility of fine-grained horizontal scalability on popular features of the app.
We are constantly experimenting with different solutions to accomplish this goal. Some of them work really well, others don’t. In order to increase our hit count we try to share our insights with other tech companies in the Vancouver area[1].
On our latest reunion we met with some great engineers from Hootsuite, and we shared and validated some of our insights about approaches towards implementing SOA.
Here are some of the salient points that came from the conversation:
Ensure well defined messaging between services

The problem:
It often happens that different services use schemas that model the same thing, but are implemented differently. Some examples of this are:
- Identifier of attributes that represent the same concept but are named differently across services (e.g.
idoruuid). DateTimevalues are serialized differently between services (e.g. service A uses RFC3339, and service B uses ISO-8601).- Some types may have different interpretations and there is no clear consensus on which one was chosen. (e.g. On a
DateRangetype, the startDate and endDate values may be in an inclusive, exclusive or mixed range). - Service A sends message to Service B, but Service B changed the way it interprets messages.
Our solution:
We need a specification that:
- Is able to support different versions of messages with backward compatibility.
- Validates all types of values transmitted between services and documents what their semantic meaning is. Also, we want to be particularly strict on the outgoing messages.
There are different ways to address these challenges. Unbounce decided to use json-schema given that JSON is a standard format in most web services out there, is simple, and it adapts well to our business problem.
We take advantages from json-schema by using a root schema that defines common data-types and then make all our services extend from these. Every team that has to use common data types doesn’t need to reinvent the wheel, they just need to go to this root definition schema, learn what is available and reuse it.
For solving the versioning aspect, every message that is sent from our services has to have a schema with a revision number, every time the revision is bumped, we ensure that new json-schemas are permissive enough to accept/ignore old schemas.
Define well established interfaces for APIs
The problem:
In an SOA system, there are likely going to be many APIs, and having a different way to document each of them is going to cause a lot of unnecessary pain in the long run. We want to be able to update interfaces and spec together, and be explicit about what version is being used.
Our Solution:
Ideally we will like to have a single approach to define our API capabilities between services, so that developers can figure out what is available quickly without re-learning different programming language specific tools.
There exists at least two well known solutions to define specs for an API: swagger and RAML. The difference between these two libraries is that one infers the Spec from the implementation (swagger) and the other defines the spec on a YAML file (RAML).
Here at Unbounce we chose RAML as our solution, for the following reasons:
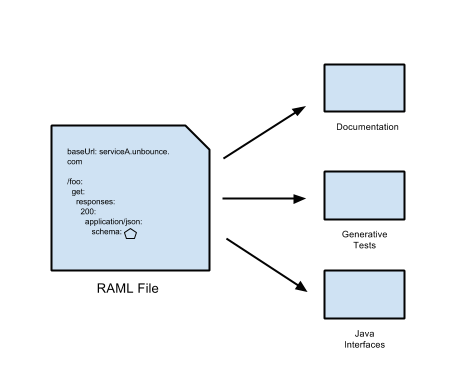
- Given that RAML is just data, we have the possibility to transform it into different products related to the service (e.g. Generative Tests, Lightweight endpoints in Ruby using Grape or Rack, Java Interfaces, HTML documents, etc).
- RAML can re-use part of the json-schema definitions and use them as part of our API spec.
Not all of this features are currently available, but it is our plan to tackle these issues in the not too distant future.
The Façade layer to compose services
The Problem:
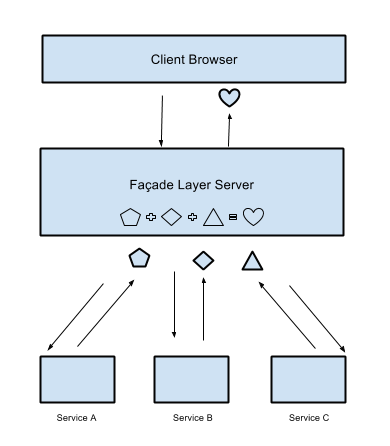
Clients need to gather data from different services to create meaningful information for our users. All these services respond at different times, and may fail in the process. Handling all this asynchronicity is hard.
Possible Solutions
This a common problem for many companies adopting SOA. Netflix has documented a great approach to solve this issue using Reactive Extensions (Rx), this is a technology that allows them to compose different asynchronous services together, and provide a clean interface for their different clients.
Another approach is to use the Typesafe’s stack, using Akka and futures to accomplish the same asynchronous composition that Rx provides.
There are other interesting solutions like the Haxl library developed by Facebook. This library allows them to compose different services that track SPAM rules using a high level API that abstracts away explicit concurrency, caching and batching.
We are working hard to arrive at a solution that works well for our developers and provides good business value.
Conclusion
As everything, building SOA systems is a game of tradeoffs, we gain a lot of flexibility with this design, but we also inherit complexity to manage polyglot systems. All in all, it is always fun to share our experiences taking a stab at the problem; hopefully in the process, we can help others to validate or learn different approaches on solving common issues.
–Roman Gonzales, Developer
[1] We learned this was a great approach to validate ideas after the PolyglotConf